组合聚类算法研究与实验+文献综述(2)
时间:2018-07-13 09:04 来源:毕业论文 作者:毕业论文 点击:次
图1.1 聚类代表算法 本次研究综合运用数据挖掘、C程序设计、数据库技术等相关知识,将所学理论知识灵活应用于实践环节。通过文献查找、阅读和归纳分析,掌握,设计出所需要的组合聚类算法。本文首先综述近年来的相关研究成果;然后介绍此次研究的基本思路与框架;再对用到的各种技术进行详细说明,主要包括K-MEANS、K-MEDOIDS、OPTICS、DBScan等四种聚类算法生成聚类成员,NMIBDM、EBDM、CMP等三种度量标准;使用投票法和超图划分的方法设计一致性函数,对所得到的单一聚类算法和集成聚类算法的结果进行对比评价分析;最终得到准确率高于单一聚类算法的集成聚类算法。 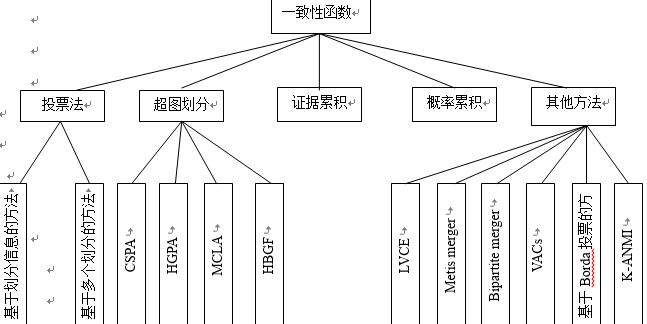 图1.2 一致性函数代表方法 2 集成聚类研究现状 设有数据集合D,首先对数据集D运行N次聚类算法,得出N个聚类成员,P={P1,P2,,PN}其中 为第i次运行聚类算法的聚类结果。然后使用一致性函数T将集合P中的聚类结果(即,聚类成员)进行集成,得到一个新的数据划分P`。因此聚类集成研究主要包括两个方面的问题:1)如何生成多个不同的聚类结果(即,如何生成聚类成员);2)如何设计有效的一致性函数,得到比单一聚类算法更加准确的数据划分结果[5]。 2.1 生成聚类成员 集成学习的过程中,各集体之间的差异程度是影响集成结果的重要原因之一[13]。聚类集成的第一个步骤是生成若干个有差异性的聚类划分结果,差异性的存在可以从不同的角度展示出数据集的构成,有利于生成更好的集成聚类结果。这一步骤的主要任务是对数据集或者它的子集运行多次聚类算法。 2002年,Fred等人[14]采用K-MEANS算法, 设置不同的k值,首先随机产生一个合理范围内的k值, ,其中 , (n为数据集中数据对象数目),然后利用K-MEANS算法生成多个聚类成员。 2003年,Fern等人[15]在解决高文数据的聚类集成问题时利用了随机投影技术。第一步,将高文的数据随机投影到低文的空间中,得出若干子集;第二步,通过EM算法对步骤一中得到的子集分别进行聚类,获得聚类成员。 2004年,Topchy等人[19,20]使用抽样的方法设计了一种自适应的动态聚类集成方法,这种集成方法将数据集中的数据设置不同的重要性,首先进行了两次取样,第一次抽样中抽到任何数据的概率相同;第二次取样时,在第一次取样中聚类结果不一致的区域取样概率更高,从而得到数据集的不同子集。 2005年, 周志华和唐伟等人[16]对产生的聚类成员进行了筛选。第一步,使用引导程序对数据集合进行采样,得出不同的子集,分别对子集运行K-MEANS算法,得出多个聚类结果;第二步,通过规范化互信息(Normalized Mutual Information,NMI)计算出每个单一聚类划分的权重;第三步,将权重符合预定义要求的聚类结果选为最终的聚类成员。 2006年,Zhou等人[17]使用K-MEANS算法 ,不改变k的取值,将算法运行N次,得到N个划分结果。 2007年,Gionis等人对同一个数据集使用了K-means、AL、SL、CL以及 Ward.s clusterings等5种不同的聚类算法产生具有差异性的聚类成员。 2.2 一致性函数 一致性函数是一个将聚类成员进行合并(或称为集成)的函数或方法,利用这个函数最终可以得出统一的聚类结果[6]。目前存在一致性函数有很多,例如投票法、超图划分、概率积累、证据积累的方法等[6]。 2.2.1 投票法 2001年,Fred[18]提出在若干个不同的数据划分中可以找出相同的划分结果。通过不同聚类成员对数据的划分,计算将两个数据点分配到相同簇中的次数,当作进行投票时是否认为这两个数据点属于同一簇的依据。如果超过50%的投票数认为两个数据点属于同一个簇,那么就将它们分配到同一簇中,由此提出了使用共协矩阵(Co-association matrix)作为相似度度量矩阵的方法。共协矩阵的定义为: (责任编辑:qin) |