
1.2 OpenCV开源机器视觉库
本文作者使用了OpenCV(Open Source Computer Vision Library)开源图像库。1999年,OpenCV由Intel建立,如今由Willow Garage提供支持。OpenCV是一个开源的、免费的计算机视觉库,可运行于Linux、Windows和Mac OS等多种操作系统。它由一系列 C 函数以及少量 C++ 类构成,同时也提供了Python、Ruby、MATLAB等语言的接口,从而实现了图像处理和计算机视觉方面的通用算法[2]。
本文作者选用OpenCV视觉库,主要原因如下:
(a) OpenCV可以跨平台,可移植性好。它可以支持 Windows、Linux、Unix及MacOSX等操作系统,可以在VS下工作;
(b) 独立性好。OpenCV拥有500多个函数,不依赖于外部库,既能独立运行,也能在运行时使用其他外部库;
(c) 源代码完全公开。程序员可以对源代码进行修改,并在库中添加自己设计的新类,自己的代码可以分享给别人使用;
(d) 具备强大的图像和矩阵运算能力。OpenCV具有大量处理函数,可以减少程序员的工作量,从而提高开发效率和程序的可靠性;
(e) 运行速度快,OpenCV使用了优化过的C和C++代码,提升了计算机的运行速度。
总之,使用OpenCV视觉库,开发人员只需要添加自己编写的程序,直接调用库中的函数即可实现有关功能,这样不但降低了开发难度,而且缩短了程序的开发周期。
1.3 本文的主要工作
本文重点研究车牌定位、分割和识别时使用不同方法的效果,比较各种方法的优劣势,以寻求能达到更好的识别效果。车牌处理的难题在于受光线等外部环境以及车牌区域污染等状况的影响增加了识别的难度,本文旨在研究能够适应各种环境的车牌识别系统的算法,使车牌识别系统的具有更好的鲁棒性。
本论文的内容安排如下:第一章介绍了车牌识别技术的应用背景和发展前景;第二章给出了车牌识别系统的总体流程图,并简要介绍了车牌的定位、分割以及识别的方法;第三章,介绍了车牌定位的原理以及相关算法,包括车牌图像的预处理,边缘检测,形态学操作和轮廓提取等。其中,作者重点比较了不同的边缘检测方法对定位效果的影响。针对依靠尺寸和角度判断筛选不完全的情况,提出了使用SVM模型进行判断,从而使定位的准确率大大提高;第四章,作者介绍了连通域字符分割法和BP神经网络字符识别法。对于不连通的汉字,作者采用了先分割出代表城市的字符,再用逆推法分割汉字的方法,解决了不连通汉字难分割准确率低的问题;第五章,运用MFC和OpenCV实现了车牌识别系统用户界面的设计。由于MFC无法显示Mat格式的图片,作者将Mat格式转换为可以在MFC中显示的CvvImage类格式。针对车牌图像过小增加了图像缩放与拖动功能,实现了人性化设计。
2 系统总体结构设计
2.1 车牌识别系统的组成
智能车牌识别技术是利用车辆的动态视频或静态图像进行车牌号码自动识别的模式识别技术。车牌识别技术的核心有车牌定位、字符分割和字符识别。
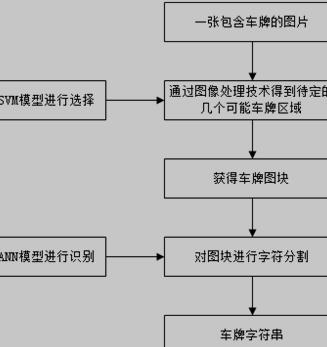
图1.1 车牌识别系统的总体流程
2.2 车牌识别系统的实现步骤
2.2.1 车牌图像预处理
图像预处理在车牌识别过程中是必不可少的环节,预处理的效果会直接影响到最后的识别率。受光照以及摄像机曝光不足等影响,车牌图像可能会对比度不足,使图像细节难以分辨,严重影响了后续字符识别过程。因此,此类车牌图像需要先进行图像增强。当车牌图片受到前景、背景噪声以及铆钉干扰时,图像质量也会降低,在这种情况下,需要对图像进行滤波以去除噪声。车牌图像由字符和背景组成,当光照均匀时,利用一个合适的阈值进行二值化,从而可以将字符和背景分开。 OpenCV智能车牌识别系统软件设计(2):http://www.youerw.com/zidonghua/lunwen_20651.html